A More Human Approach To Databases
Motivation
End-user databases are all the buzz these days — Notion, Airtable, Coda, Roam, etc. These products have made it possible for people to model information in a way that feels more natural and intuitive to the way we experience it in our daily lives.
I love building products like Notion, but building these kinds of products is hard. For two reasons:
- Most people don't have the technical literacy about databases and information architecture to actually automate and organize their lives with these tools.
- The databases we have today aren't well-suited for dynamic user-generated filters and sorts.
This second challenge is more technical and I will hide all of these programmer-related details behind a toggle so you don't have to read them if you'd like.
-
🤖 Technical Details
Underneath any end-user database is another database and so much complexity arises from the challenge of building a database inside a database. Solutions to this problem vary widely and make some sort of trade-off between scalability (performance) and complexity.
Some applications load the entire end-user database in-memory. This creates long initial load times, but really performant interactions once the application loads. There are obvious scalability issues with this approach, but it is fairly simple to implement.
Other applications resort to O(n) scans on the server to fetch data and filter/sort records in memory with a few caching and indexing optimizations when convenient. The problem here is that users can create their own columns and filters dynamically. If your cloud application is backed by a SQL database, for example, it’s worrisome to allow users to edit the database schema and create an unbounded number of tables and indexes. Thus, you must resort to filtering records in-memory.
If you're dedicated to O(log n) queries, you'll need to build indexes yourself (unless there's some amazing database I am unaware of). On every write, you can compute what indexes need to be updated and you write to a NoSQL database to incrementally update a cached query result. This can lead to a good solution, but it comes at the cost of consistency. Now that you're building your own indexes outside of the database, writes are no longer transactional and you lose the guarantee of being able to read your own write.
Another solution is to have a separate database for every user and allow users to edit the schema of their own isolated database. This allows writes to be transactional, but creates other kinds of collision problems (i.e. dealing with merge conflict) when you want users to be able to collaborate. With separate databases for each user, you're also doing a lot more computing labor, especially if the same records are shared amongst many people.
Long story short, existing databases are not great for building end-user databases.
I plan to address this first reason by giving you a mental model of what databases are and a first-principles understanding of how they work.
I'll introduce databases as an abstract concept and then we'll work through a real-world example to explore how databases leverage sorting and filters to lookup information quickly.
By the end, I hope to show you how these information architecture concepts are immensely powerful and totally approachable for non-technical people.
Lastly, I want to convince you that software based on these concepts will be far superior to anything we use today for end-user database applications. If these concepts are interesting to you, please reach out! I love sharing ideas. 😁
What is a database?
Databases are filing cabinets.
Databases don't have to be so complicated. If you strip away all the fancy semantics, you end up with something simple and familiar.


Dictionaries, calendars, and filing cabinets are particularly useful because they represent information in a sorted order, making it possible for us to retrieve information quickly and efficiently using a process called binary search. Databases are no different, they're also containers of sorted information.
What is sorted information?
Alphabetical, numerical, compound, lexicographical Encodings.
The simplest way to sort something is alphabetically (a.k.a lexicographically) and this is how words are sorted in the dictionary. But we often find ourselves sorting by more than one property. For example, a contact list is often sorted by last name, then first name. This is called a compound sort.
For example, notice that "Thomas Robins" should come before "Charlie Robinson" when sorting this way and that a compound sort is fundamentally different from simply joining the words together and then sorting.
// Compound Sort: Last, First
Robins, Thomas
Robinson, Charlie
// Joining the words, then sorting: Last + First
RobinsonCharlie
RobinsThomas
We do this kind of compound sorting all over the place. Dates, in particular, are compound sorted by year, then month, then day.
January 10, 2019
...
December 28, 2019
...
August 26, 2020
...Notice that this kind of sorting isn't exactly alphabetical. The months in a year are definitely not sorted alphabetically — each month has an underlying order within a year. Even days of the month aren't alphabetically sorted — they're numerically sorted.
Numerical sorting is different from alphabetical sorting because alphabetical sorting compares letter-by-letter. For example, if we sorted numbers alphabetically, then 10 would come before 2 because the first digit "1" is before "2".
// Alphabetical Sort
1
10
11
2
3
...
9
// Numerical sort
1
2
3
...
9
10
11A simple way to represent numbers in a way that can be sorted alphabetically is to put zeros at the beginning of the number. This works well for small numbers with a known maximum size such as the months in a year.
// Zero-padded numbers representing months in a year.
01
02
03
...
09
10
11
12And in fact, we can represent dates in a way that can be sorted alphabetically using ISO 8601 date format.
2019-01-10
...
2019-12-28
...
2020-08-26
...
Representing dates this way is convenient because it doesn't require domain knowledge to understand how to sort them. There are an infinite number of things that can be sorted arbitrarily: a deck of cards, the status of a project, your rock collection—they are all just different types of things.
In general, lexicographical encodings are important because they allow databases to store arbitrary information in the correct order without needing additional knowledge about the type of information that is being sorted.
-
🤖 Technical Details
You've probably experienced frustration with this when looking at files in your filesystem. Natural sort solves this problem elegantly by representing both alphabetical and numerical sort at the same time.
Representing numbers as lexicographically sortable is another interesting challenge, particularly very large and very small numbers. Elen is an interesting approach for encoding floating precision numbers.
Tuples can be represented as compound sortable by separating each item with null-byte (and escaping null-bytes inside each item).
Fractional sorting is a very related and interesting topic as well.
Administering a Police Department
You can think of databases much in the same way you think of system filing cabinets. To explore this analogy further, let's imagine that you are in charge of administering a police department where you keep track of a variety of information about every police officer in your region — name, badge number, address, and precinct, among other details.
As the administrator of this information, you're responsible for making sure that everything is up to date and easily accessible.
To keep things simple, you start by keeping all officer information in a filing cabinet sorted by badge number. This makes it easy to retrieve information about any officer based on their badge number, for example when an officer gets promoted or moves to a new address.
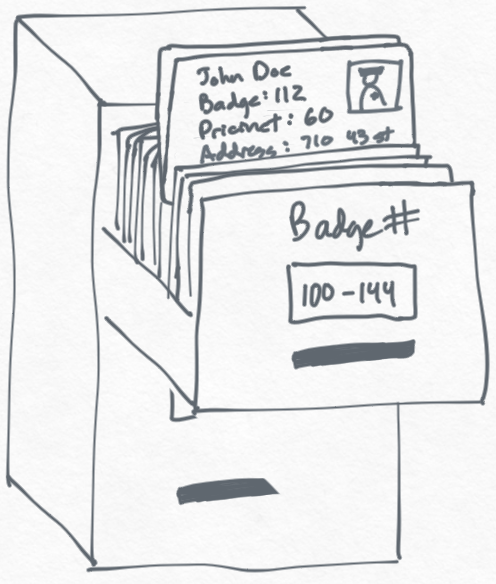
Read/Write Trade-off
How we copy information into other cabinets.
One day, the police chief asks you for the address of every officer in the 60th precinct.
With all of this information in a single filing cabinet sorted by badge number, this is a painful request because you have to scan through every file and check if each officer is in the 60th precinct.
Maybe this is just a one-time request so you can labor over it and be done with it, but the police chief says that every month he wants to mail a bonus check to every officer in the precinct with the most arrests. If you're going to have to do this every month, maybe it's worthwhile to make this job a bit faster.
To solve this problem, you create another filing cabinet where you sort all officers by precinct. To keep things simple, you photocopy all of the information in the Badge # cabinet over to the Precinct cabinet. Now when the chief asks you to get the address of every officer in a precinct, you can use this new filing cabinet to quickly retrieve the information.
This new filing cabinet makes it easier for you to get information, but you've created a new problem every time you have to update the information. If a new officer joins a precinct or an office moves from one precinct to another, you now have to make sure the information is correct and updated in two different places.
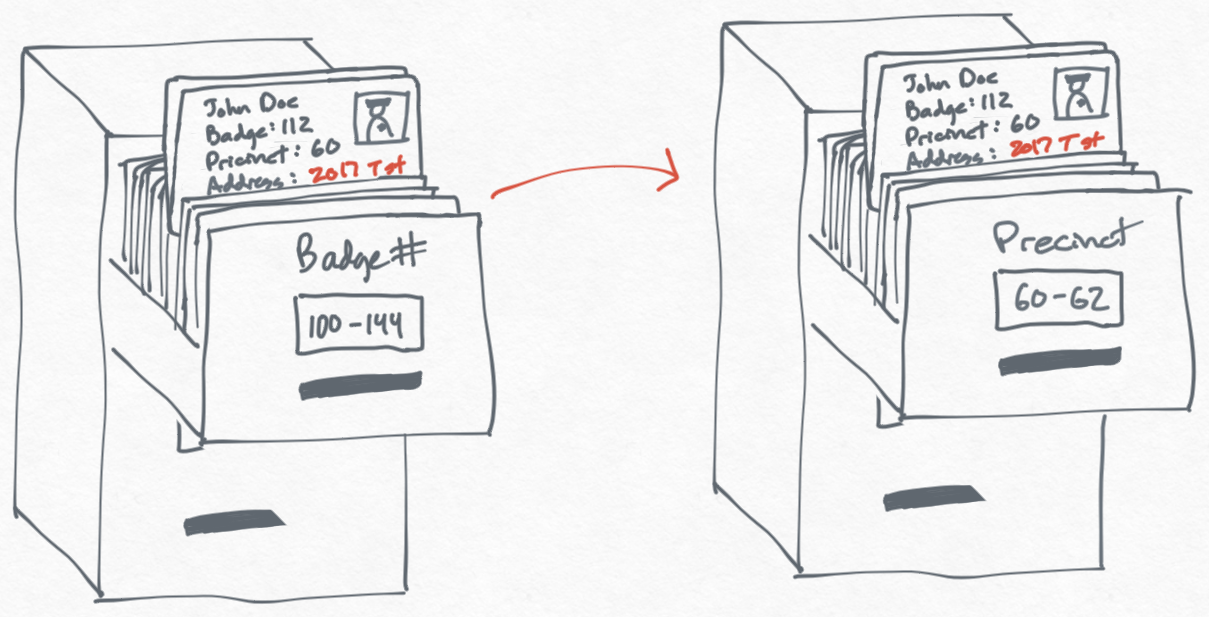
Making things worse, we end up wasting time keeping unnecessary information up to date. For example, maybe we don't need the date of birth or a photo of the officer in the new Precinct filing cabinet we made, but we copy it over anyway so the information doesn't get out of sync.
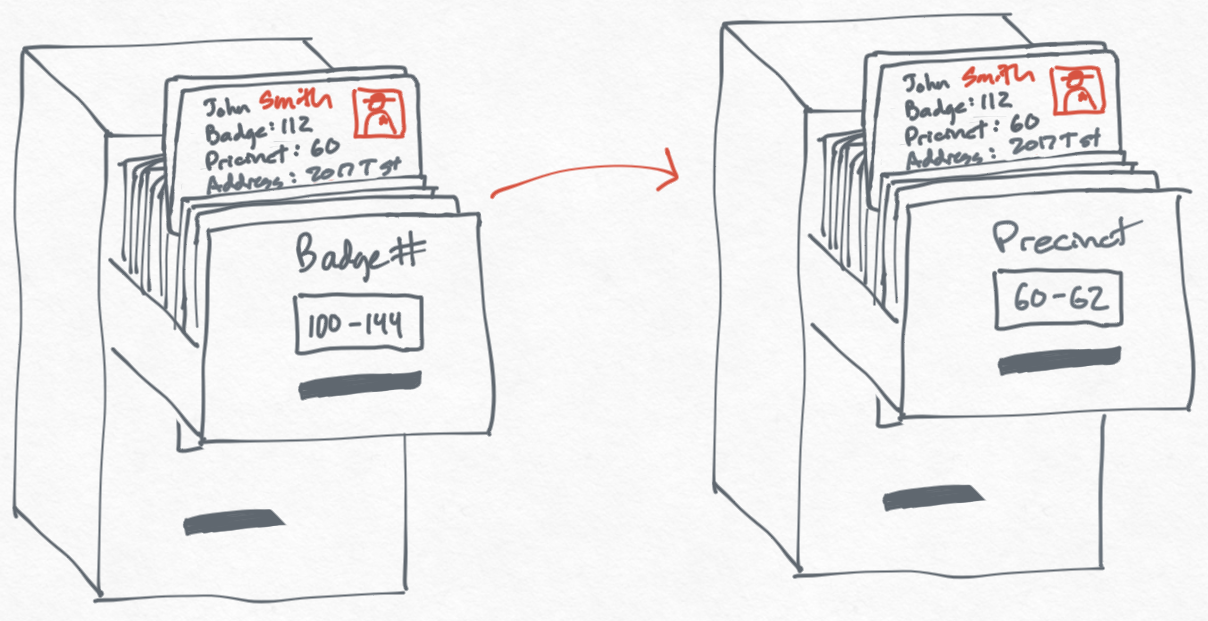
On the other hand, maybe we decide that the only information we store in the Precinct cabinet is the badge number. This makes changing and managing information about the officers require much less work — we only need to update it in the original Badge # cabinet. It also means that the Precinct cabinet is much smaller because we don't have as much information crammed in there.
But there's a catch. Now if you need to get the address for every officer in a precinct, you'll have to first use the new filing cabinet you made to get the list of officers in the precinct and then you'll have to use the original Badge # filing cabinet to get the address for each officer. This is still quicker than not having a Precinct cabinet, but not as fast as the previous approach for scanning through every officer's file.
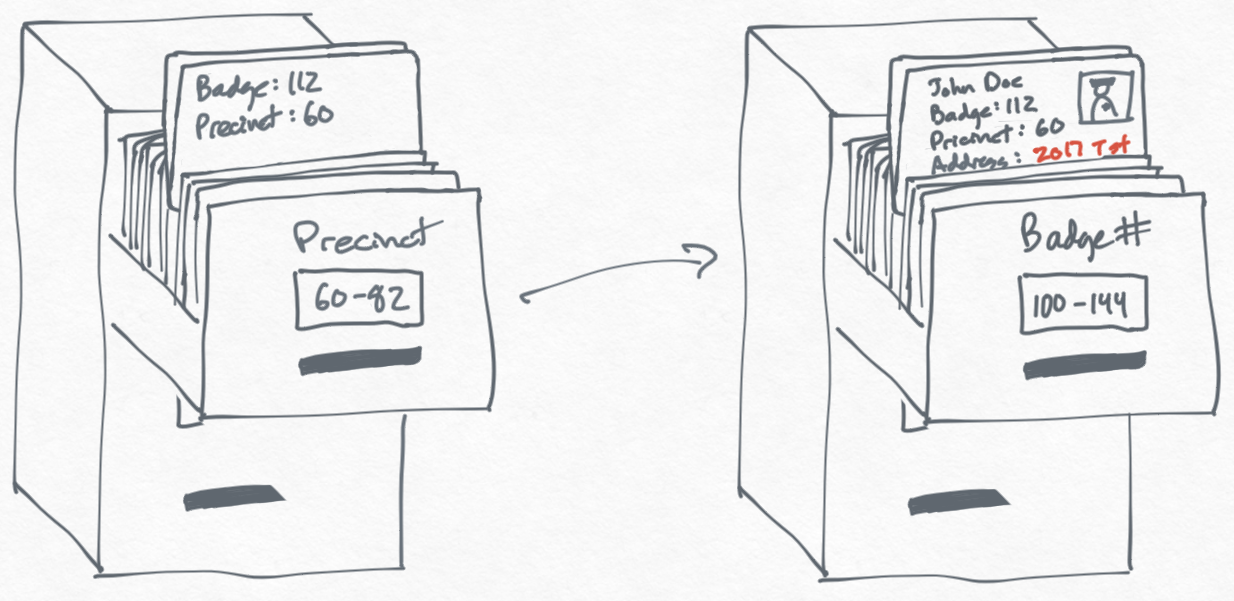
Fundamentally, there is no "best" way to do this — it's all a trade-off between how much work you want to do when reading vs writing information.
There is a middle ground between these two approaches where we record both the address and the badge number in the new Precinct filing cabinet we created. This strikes a nice balance where we don't have to update information that we don't care about in the Precinct cabinet.
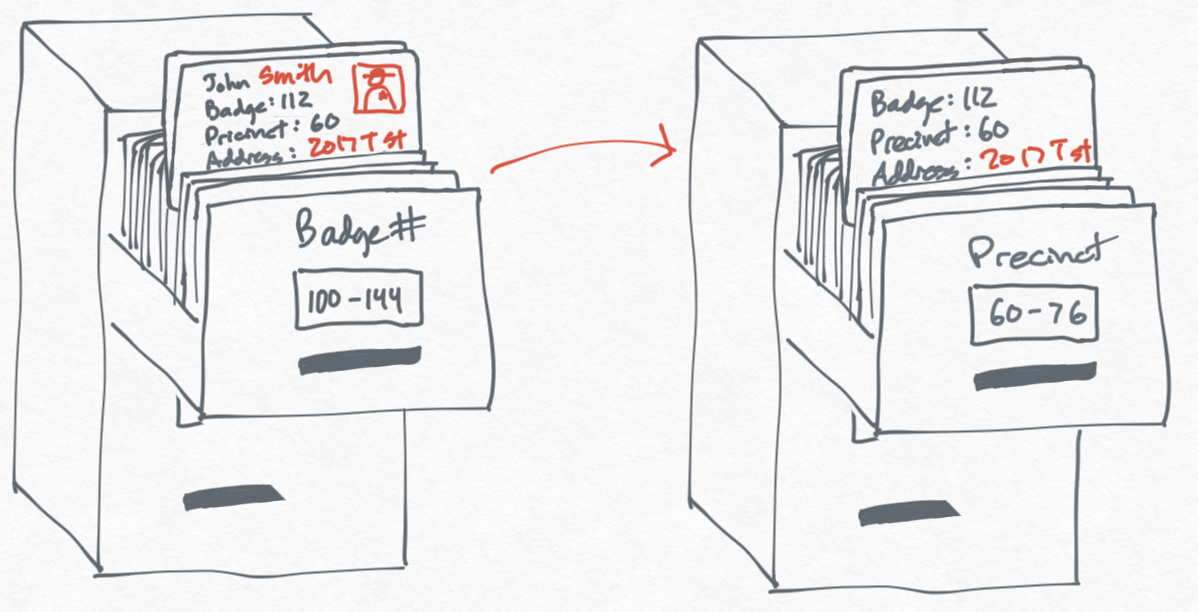
However, this does come with some logistical overhead — now we have a list of procedures we have to follow when updating the Badge # cabinet:

-
🤖 Technical Details
There is a direct analogy here with SQL. The Badge # cabinet is the officers table with the badge number as a primary key. The Precinct cabinet is an index on the officers table.
And the procedures list is just the list of SQL indexes on the officers table defined by the database schema that internally needs to be updated whenever an officer is updated.
This procedures list will also include SQL triggers on the officers table. While SQL does not let you create indexes on information joined across tables, you can effectively achieve this with triggers.
Query Planning
Determining how to answer a question with existing filing cabinets.
Now let's suppose that whenever someone files a complaint against an officer, we want to make note of the complaint in the officer's file. Often times, when someone files a complaint, they don't have the badge number for the officer but they do have the name of the officer.
To make it easier to look up officers by name, we create another filing cabinet to sort all officers by name. Our filing system now looks like this:
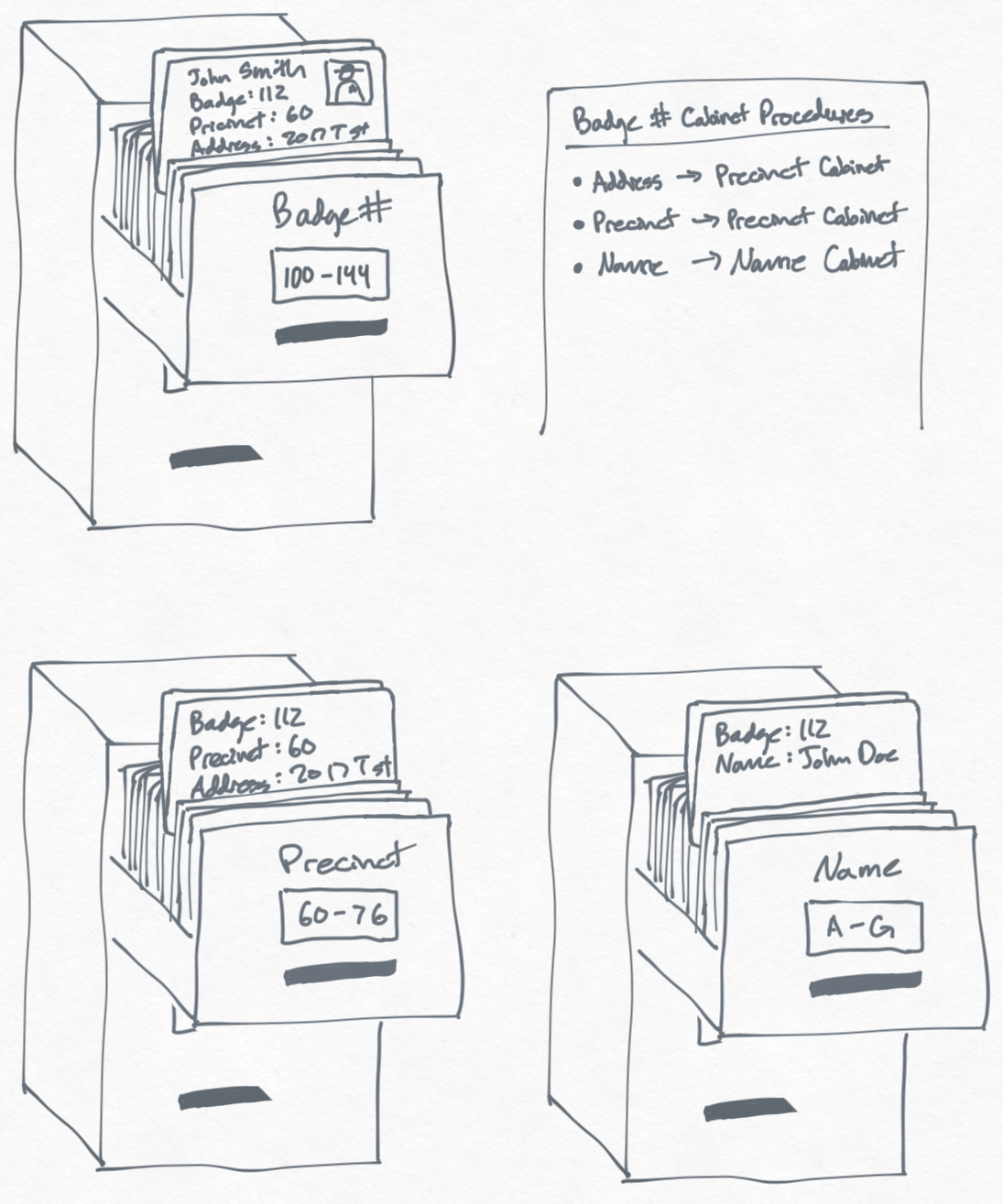
Now let's imagine this police department grows from 10k officers to 10M officers. You receive a complaint for Officer Smith with brown hair, blue eyes, from the 121st precinct.
You're considering two different ways of looking up this officer — you can either scan through every officer in the 121st precinct looking for Officer Smith or you can scan through every officer with last name Smith looking for the officer in the 121st precinct.
You make an assumption that there are probably fewer people with the same name than there are people in the same precinct, so you decide to first look up the officer by name.
In databases, this process is called query planning: you have a question (some information you want to retrieve) and an existing filing cabinet setup, and you need to determine the quickest way to gather all of this information.
-
🤖 Technical Details
The trade-off we just considered by intuition is exactly what a SQL database's query planner does. The query planner uses heuristics about how distributed the data is in different columns in order to choose which index to scan that will have the smallest amount of results.
That said, heuristics aren't perfect and it's totally possible that there are more officers with last name Smith than the number of officers in any given precinct.
So you look into the Name cabinet that you created and end up finding out that there are actually hundreds of officers named Smith in the 121st precinct. Once again, you decide it's worth figuring out a faster way to do this.
What you want is something like the Precinct cabinet that you created with a secondary sort by officer name. But the Precinct cabinet doesn't include officer names, so you would have to create a new filing cabinet to include them. You decide it's probably more efficient to just copy the officer names over to your existing Precinct cabinet and sort by name to save some space.
As we discussed earlier, this is a compound sort since we're sorting on more than one property: precinct, then name.
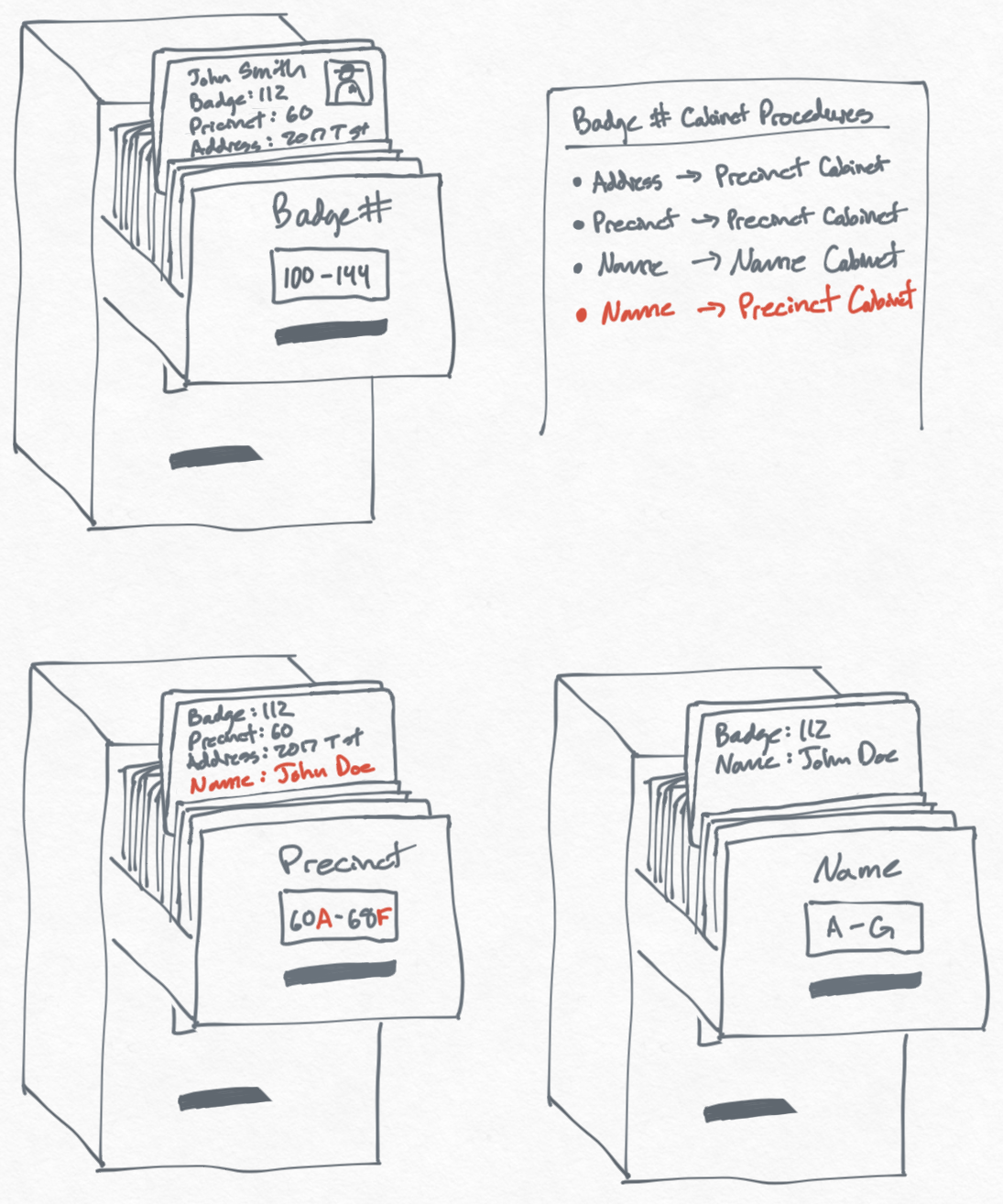
Procedure Cabinet
Automating internal mechanisms.
In response to public outcry about skyrocketing officer complaints, the police department has hired local auditing firms to audit each precinct. Now whenever information about an officer is added or modified, we need to notify the auditing team assigned to the officer's precinct about the changes.
We start to write out these procedures on the same list as before, but we start to realize that this is going to be a really long list of procedures.

Every time we make a change to the Badge # cabinet, we now need to scan through this huge list of procedures and it takes too much time. So what we do is quite simple, we move all of the auditor addresses into a new filing cabinet and add a step to our list of procedures that tells the clerk where to lookup the auditor's address.
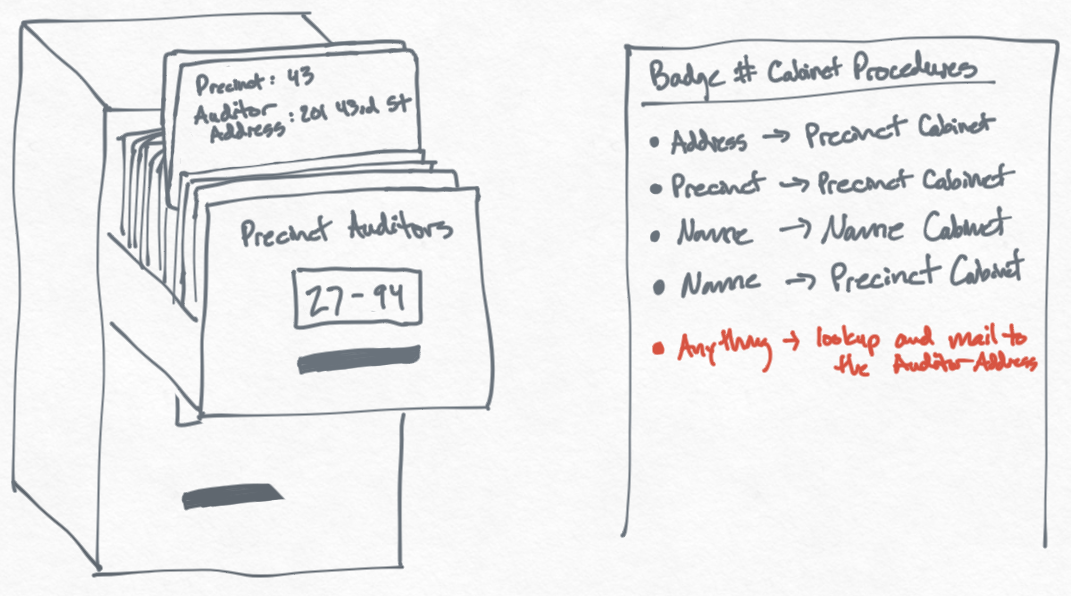
This is much more manageable, but as you can imagine, the procedure list will keep growing as the organization evolves in complexity; the HR department wants to know whenever an address changes or a complaint is filed; the Finance department needs to know whenever an officer is promoted so they can adjust their paychecks appropriately — the list of procedures goes on.

Hopefully it's not too hard to see that this procedure list itself can be turned into a filing cabinet sorted by property. That way, we don't need to read through every procedure for every property when we're just updating an address. Therefore, whenever we make a change to the Badge # cabinet, we lookup every property that changed in this Procedures cabinet to see what we need to do.
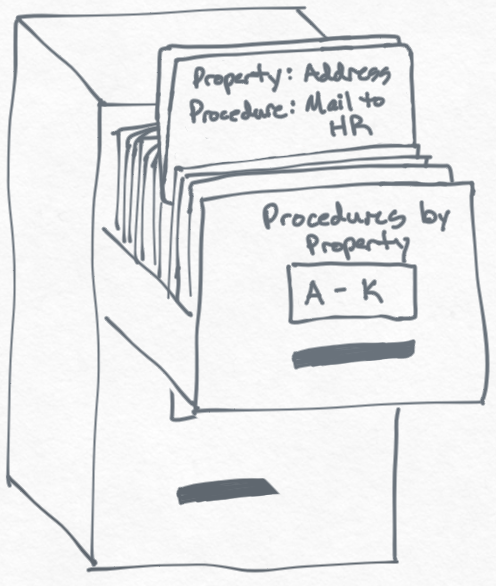
-
🤖 Technical Details
This abstraction is a fundamental limitation of SQL and most database systems. In SQL, every trigger goes into a procedural list, even conditional triggers. This means that every additional trigger is going to linearly slow down every write.
You can do things like keep the list of auditor addresses in a separate table rather than create a bunch of triggers, but what you cannot do in SQL is have a dynamic list of stored procedures with efficient lookups.
I think there's a very pragmatic reason for this as well: without a static list of procedures then it's difficult to predict the performance of a write without actually trying to do it, looking up the procedures, and seeing how much work it's going to be. With a static list of procedures, you can at least look at the length of the list to understand how much work is involved.
So far, we've only maintained a list of procedures for the Badge # cabinet, but there's no reason why we couldn't have the same kinds of procedure lists for other cabinets. And in fact, it's really useful to do so because it lets us partition our procedure list into more efficient ways of sorting procedures.
For example, suppose there's an ongoing investigation where the FBI wants to know if there are any changes to officers in the 50th precinct with the last name Colombo.
We could create a procedure for the Badge # cabinet that checks whenever a name or a precinct changes, then checks if it's the 50th precinct and last name Colombo.

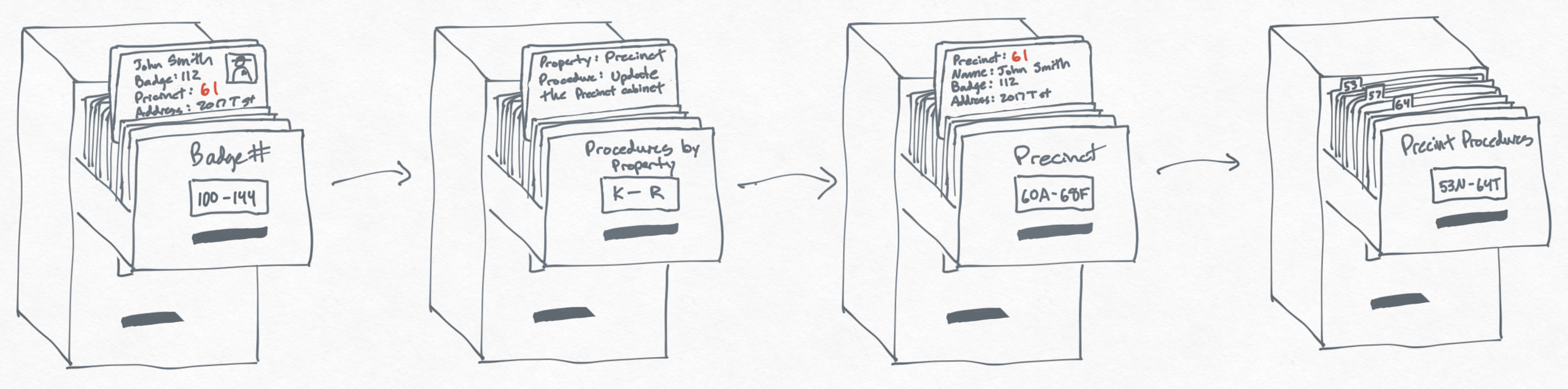
However, there's going to be a lot of wasted effort checking this procedure every time a precinct is changed. For example, suppose Officer Smith moved from precinct 60 to 61 — when you lookup procedures, you'll see this procedure and need to check for Colombo in the 50th precinct.
There's a better solution — we can create a procedure for the Precinct cabinet. Recall that the Precinct cabinet is a compound sort by precinct, then name. Thus, we can make our procedure cabinet really granular by using a compound sort for the procedures.
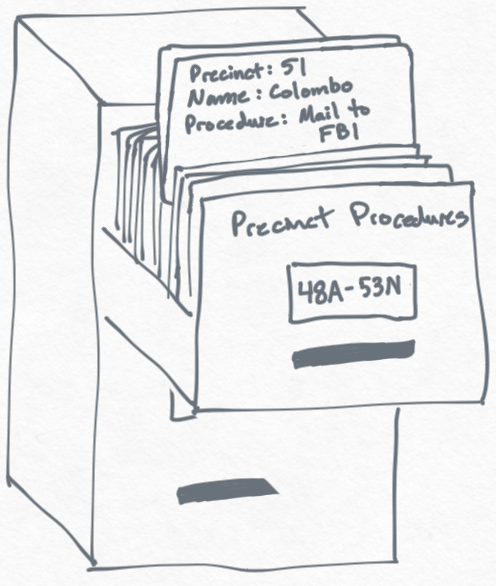
Now, when I move Officer Smith from precinct 60 to 61 (first cabinet in the image below), I will see a procedure telling me to update the Precinct cabinet, and after updating the Precinct cabinet, I will lookup procedures for the Precinct cabinet to see if there are any procedures for precinct 61 and name Smith. Notice that we are able to skip over the procedure that checks for precinct 50 and name Colombo. This is really efficient!
-
🤖 Technical Details
From a SQL perspective, this is similar to creating a trigger on an index (you can't do this, but you kind of can if you generate indexes yourself with separate tables), creating a hierarchy of updates and thus eliminating some wasted effort. Furthermore, we're creating conditional procedures that can be efficiently queried.
It's possible that we want to listen to changes for an entire precinct, not just a specific person in a precinct, and we can use this same Precinct and Precinct Procedures cabinets to do this if we generalize how this works.
Suppose we want a procedure to run for updates to precinct 51 for any name. We can add a procedure sorted by the tuple [51] which comes before [51, A]. And when we lookup procedures, for [51, Colombo], we just need to make sure that we lookup not just [51, Colombo] but for all prefixes a well — in this case, [] and [51]. Note that [] means "any change to this filing cabinet".
Procedure lists and being able to efficiently lookup what procedures you need to do when updating a cabinet is a really powerful abstraction for automating information systems. Even more, this abstraction goes beyond the capability of existing database systems.
Audit Log
Receipts, forms, requests to change information.
There comes a time when there are so many people and so much information changing that it becomes important to keep track of all the details around who is changing what and when.
For example, maybe you open up the file for Officer Jones and it says he is a detective. And maybe you thought he was just a deputy, so you might be inclined to ask questions like "when was he promoted?", "who promoted him?", and "how many promotions were there this year?".
These questions are impossible to answer with our current setup and you can imagine that if you were administering a bank, you'd be asking these kinds of questions all the time about the movement of money between accounts.
At a bank, every transfer between accounts is going to be documented with some sort of receipt that gets saved forever. And at our police department, changing any information might be documented with some kind of form. For example, when the police chief wants to promote Officer Jones to detective, he fills out a "promotion form" and delivers it to the filing clerk at the administration office.
The filing clerk might put this form in a filing cabinet for promotion forms sorted by rank and then date. Then we look up a set of procedures for this promotion, one of which is simply updating the rank of the officer in the Badge # cabinet.
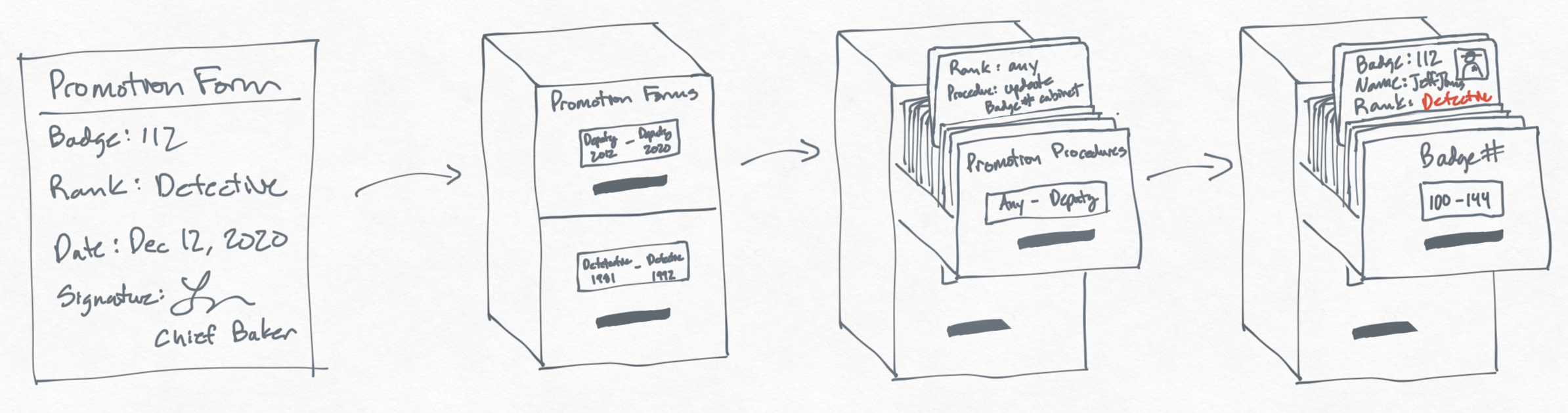
This process definitely requires more work than simply updating the officer's rank in the Badge # cabinet, but it allows us to audit changes and answer a broader set of questions about how things have changed over time. For example, we can look at all promotions by rank over time from the Promotion Forms cabinet. And if we wanted to determine when an officer was promoted, we can create a separate cabinet that sorts these promotion forms by badge number, then date.
When keeping a historical list of changes for auditing purpose, it's often important to build mechanisms to make sure that the information is not tampered with.
For example, suppose a bad actor wants to secretly add a record showing that Officer Jones was demoted on Dec 11 prior to being promoted on Dec 12 (perhaps to create a fraudulent scandal they can write about in the news to discredit the police chief before an election).
Signatures are the first line of defense here. If a signature is hard to copy, then it will be hard to create a fraudulent demotion form (note: we're using the same promotion form for demotions as well). Another thing we can do is make note of the previous rank in the promotion form. That means if the bad actor wants to create this fraudulent demotion form, they will also need to fraudulently update the promotion form of Dec 12 to reference a previous demoted rank.
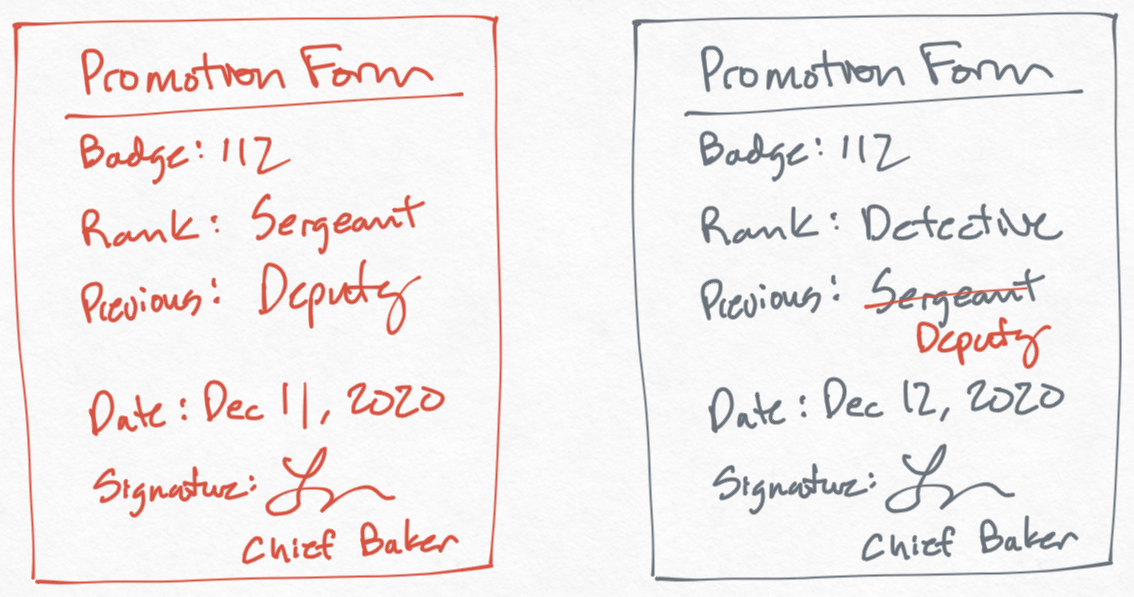
In the physical world, protecting against this kind of fraud is pretty difficult and inevitably requires some kind of trust in the system. But in the modern world with encryption and one-way hashing, we can create signatures for records that cannot be tampered with. This is exactly how the blockchain works to prevent fraudulent transactions in Bitcoin.
Beyond Filing Cabinets
Permissions, asynchronous communication, consistency, conflicts.
At this point, we've pretty much covered everything that is interesting about filing cabinets and how we can use them to manage large amounts of information with operational procedures. But there are a few more important systems needed for any realistic administration department.
The first is managing permission. Who has permission to promote an officer? Who has permission to read the complaints on a given officer? And who has permission to change the address of an officer?
There are plenty of ways to manage this and most organizations use some kind of permission hierarchy to keep things simple. I will leave answering these questions as an exercise for the reader, but if you are technically inclined, I would recommend reading about how Google solves this problem with their Zanzibar database.
Another part of the system that needs to be carefully managed is how information gets mailed around to different departments. Sending something in the mail takes time which can cause all sorts of issues in a complex organization.
For example, maybe an officer gets promoted on Dec 12 and when the finance department sends out paychecks on Dec 13, they still haven't received the promotion from the mail and so they send out a paycheck based on their previous rank.
Things get even more challenging when coordination is involved. For example, maybe the HR department determines that an officer has too many complaints and must be demoted. The HR department sends the demotion in the mail to the administration department as well as the finance department. At the same time, the chief thinks that the officer should be promoted and sends a promotion in the mail to the administration department as well as the finance department.
Now what happens? Regardless of the outcome, the most important thing is that the administration, HR, and finance departments end up with the same result (also known as eventual consistency). For example, if the finance department decides to process the promotion and the administration department decides to process the demotion, then their records will differ and the officer will receive a larger paycheck than the administration department expects.
These are hard problems to solve and I will leave it to the reader to think about how to manage these kinds of coordination problems. But if you're technically inclined, I'd recommend reading about how Automerge deals with these problems for peer-to-peer software.
Conclusion
Databases can seem quite complicated, but every database fundamentally works just like a system of filing cabinets and stored procedures. Things start to get more complicated when we need to keep information up to date in many places and we want to have an audit trail of all changes to a database. But this complexity is essential to solving the problems we addressed.
When it comes to the future of computer literacy, I know that not everyone is going to be a ninja programmer, but understanding the details of how to structure systems of filing cabinets will allow ordinary people to get the most out of computers.
-
🤖 Technical Details
From a technical perspective, there are a few important things we should consider from this analogy.
For one, there are no database systems I am aware of that efficiently query and evaluate user-generated procedures. This kind of flexibility is essential to build a scalable end-user database application.
Another thing to consider is how information is sharded. In this analogy "sending something in the mail" is effectively saying that there is a boundary between shards. That is, the HR department and the Finance department are in different physical locations.
When we're building applications for our users, where do all these filing cabinets live? One way to do it is if everyone has their own filing cabinets at home (and some people do). Another way to do it is every service you use keeps records of your information and you have to ask them for it whenever you want to see it. This is currently how most things work in the world: your health records live at your doctor's office, the blueprints for your house live at the building department, and your emails live in a virtual filing cabinet in a Google data center.
This way of doing things is actually quite convenient for many people — they don't need to keep track of their own records at all! On the other hand, it means people are less empowered to build their own filing cabinet systems to manage and automate their life. It also means that their information is less private.
If you are inspired by these ideas, want to build an embedded database, or just want to toss around some related ideas, please don't hesitate to reach out. Thanks for reading 🙏
Published January 12, 2021 by Chet Corcos
Thanks to Haris Butt and Max Einhorn for reading drafts of this.